The tests were performed over several days in Sept 2010 with Cassandra 0.6.2 utilizing the supplied contrib/py_stress tests.
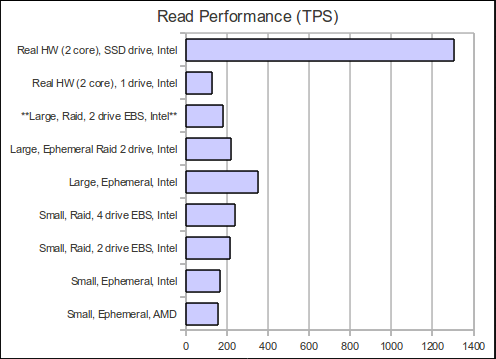
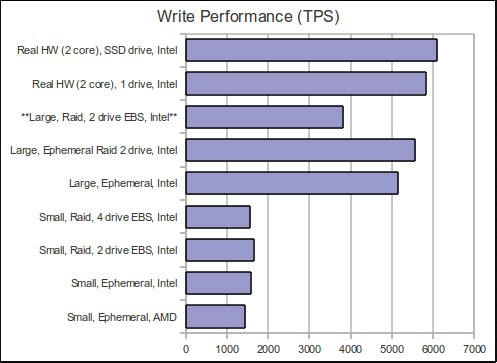
** Inconclusive results because of slow EBS drive
General EC2
Since the tests are typically large and do not fit in RAM our intent was to test EC2’s hardware performance, not necessarily Cassandra’s performance with things like cached data.As with any performance testing lets first highlight the caveats of trying to run performance tests on EC2. The variance in test results from run to run on EC2’s virtual hardware fluctuated anywhere from 6-12%. I originally set out with the hope of finding the optimal configuration settings for running Cassandra on EC2, but the test results from run to run were too random to gather any meaningful data. Please don’t take this the wrong way because I love EC2, but the beast is like a werewolf…when the moon is full you never know what you are going to get.
Not all EC2 instances are created equal. There can be a sizable difference between the AMD cores and the Intel cores. It looks like the underlying hardware for EC2 is either a “Dual-Core AMD Opteron(tm) Processor 2218 HE w/1M cache” or “Intel(R) Xeon(R) CPU E5430 @ 2.66GHz w/6M cache”. You can figure this out by running the command “cat /proc/cpuinfo”. The Intel cores can be 5-25% faster from run to run probably because of one obvious difference in the size of chip cache of 1M vs 6M. Unfortunately, the chart doesn’t show the differences that well, but for certain types of test it can be substantial and we have noticed better performance shifting our production nodes to the Intel chips.
Raid 0 EBS drives are the way to go. We didn’t notice a difference above the normal EC2 fluctuations when testing for 2 vs 4 drives. We were aware of other blog tests showing better performed with 4 drives, but we didn’t notice any measurable difference in our testing. Notice in the chart the “Large, Raid, 2 drive EBS, Intel” severely under performance when compared to the ephemeral drive and we tracked this down to a EBS problem. Using the command “iostat -x 5” we were able to find out that 1 of the raided drives was at 100% utilization while the other was only around 40% (Once again an EC2 thing…probably unlucky when we partitioned the EBS drive and got a busy SAN). We know that people have experienced a lot better performance by putting the commit log on a separate drive, but we didn’t notice any discernible difference above and beyond EC2’s normal fluctuations. We also performed a 50/50 read/write test that we hope to publish the results soon.
Small vs Large
Large instances are not 4x as fast as small instances. Large instances are 4x the price and 4x the virtual hardware, but they do not return 4x the performance. The only reason to choose a large instance over a small is for the extra RAM that gives Cassandra more breathing room for stuff like caching and compaction. If you have scenarios like ours where we use mapreduce jobs to iterate over every key in a Cassandra ColumnFamily and the data size is some multiple above available RAM then things like key cache and row cache have little meaning for us and EC2 small instances are a great value. Our production setup also has a 3-1 read/write ratio and our data insertion tends to follow periods of low load giving our small instances time to perform compaction and recover. The small instances are a lot more finicky and we have to hover over them, but we usually find ourselves hovering over the machines anyways so the cost savings is worth it.
Real Hardware
Kind of obvious, but real hardware is better…and yea SSD’s kick butt. Our real hardware tests were run on very old Dell 860 power edge servers with 1 “Intel(R) Core(TM)2 Duo CPU E6750 @ 2.66GH w/4M cache”, 2 GB RAM, and an old 250GB 7200 RPM hard drive. Out of curiosity we bought the cheapest SSD drive we could find from Fry’s electronics which turned out to be a $96 64 GB drive to run some tests with and it was well worth the money. Granted the drive was marked as “Desktop” and we have reservations about how long it would last in a production server environment, but you cannot argue with the performance results. Our view is it’s cheaper to buy 64GB of SSD drive vs 64GB of RAM and with replication factor > 2 who cares about drive failure :)
Howto
We have included all our automated scripts and documentation used to perform the tests. You should be able to configure the boxes and start reproducing the results in as little as 20 mins per run using the provided scripts. Please refer to a couple of previous blog posts describing automating EC2 setup. We ran each individual test for an average of about 1 hr before we collected results. We also include scripts to configure the client testing machines. It should be as simple as running a few cmd lines.
Conclusion
For us, running our 5 node cluster on small instances works great and the large instances are not worth it unless you must have the extra RAM for caching/compaction. BUT, we wish we had the money for real hardware and SSD drives :). Even our cheap old hardware and cheap SSD drives seemed to outperform EC2 by a considerable margin.
When we find some extra time we would like to test a small 3 node cluster vs a large 1 node cluster. It would also be nice to see how changing the replication factor affects performance.
Downloads
Cassandra performance test install script - cassandra-perf-test.zip